We just discussed the SQL*Loader type of external tables, and that is what is used by default. However, there are other types of external tables that each has its own access drivers and helps you work with the different data types you might be using.
The types of external tables are as follows:
• ORACLE_LOADER
• ORACLE_DATAPUMP
• ORACLE_HDFS
• ORACLE_HIVE
The default is ORACLE_LOADER as we just discussed. It can load data or be used in SQL statements to join against internal tables to do transformations and then load. It cannot unload data.
ORACLE_DATAPUMP can perform both loads and unloads of data in binary dump files. Even the files that are written can be read back into the database.
ORACLE_HDFS extracts data in a Hadoop Distributed File System (HDFS), and ORACLE_ HIVE extracts data from Apache Hive. Both of these are useful for big data platforms and working to pull data into your Oracle internal tables for further analytics and machine learning.
Creating External Tables
There are a couple of setup steps that are needed for external tables. You need a directory. The location of the files is defined by the directory object. The location is the data files for ORACLE_LOADER and ORACLE_DATAPUMP types.
Access parameters are also needed, which is related to the type of external table. We mentioned that each of the types has its own types of access drivers.
Loading CSV Files into the Database
You can load small or very large CSV files into the database, using external tables and SQL. You can also use other file types, but based on the use case and need, there might be other ways to more efficiently load data such as JSON or other data. It also depends if this is a one-time load or a regular process that is being automated with external tables.
Figure 15-1 shows the architectural components involved with using an external
table to view and load data from an OS file. The CREATE TABLE…ORGANIZATION EXTERNAL statement creates a database object that SQL statements can use to directly select from the OS file.
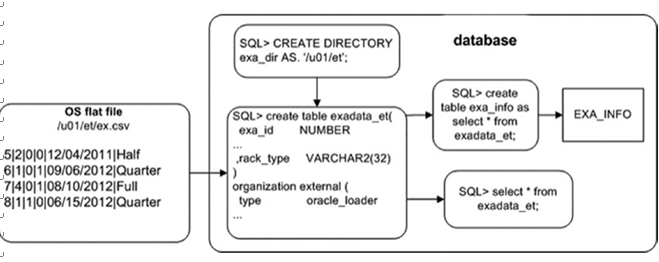
Figure 15–1. Architectural components of an external table used to read a file
Here are the steps for using an external table to access an OS file:
1. Create a database directory object that points to the location of the CSV file.
2. Grant read and write privileges on the directory object to the user creating the external table. (Even though it is easier to use a DBA-privileged account, with various security options, access to the tables and data might not be available to the account. Permissions need to be verified and granted as needed as this is probably a load process that should not have DBA privileges.)
3. Run the CREATE TABLE…ORGANIZATION EXTERNAL statement.
4. Use SQL*Plus or other SQL tools to access the contents of the CSV file.
In this example, the file is named example_sales.csv and is located in the /oradata/sales directory. It contains the following data:
4|19|1097578|iphone|discover|1/19/2023|2.99 9|2670|1212876|mac|amex|1/11/2023|3.99 8|1037|1164794|galaxy|mastercard|1/21/2023|2.99
Wasn’t this supposed to be a CSV example? Of course, but that is just a delimited file, and some of the delimiters can be different than commas and separated by characters like a pipe (|). The character depends on the data and the user supplying the file. A comma is not always useful as the delimiter, as the data being loaded may contain commas as valid characters within the data. A fixed field length can also be used instead of using a delimiter.
